NetBeans
First, there's NO Java coding needed nor Java source code needed to profile a Java program this way. NetBeans added this a while back up I just found it recently. The ability to attach to any Java program and profile the SQL going across JDBC. The dev team's blog on it is here: http://jj-blogger.blogspot.nl/2016/05/netbeans-sql-profiler-take-it-for-spin.html
SQLcl
SQLcl is our Java library for scripting sql/sql scripts that has been in SQLDev since day 0 back in '05/06. We factored that and wrapped a cmd line around it. This makes it easier to test for features, regressions, performance,.... as well to give a new cmd line with extended features. This library is also what performs the Grid Infra installs these days as well embedded in Oracle REST Data Services. It's quite proven and tested. This is all Java bases using plain JDBC to talk to the database. It's no different than any java based application which means anything done to profile it is applicable to any java program like say sqldev , ords, custom jdbc , any java program.
Profiling
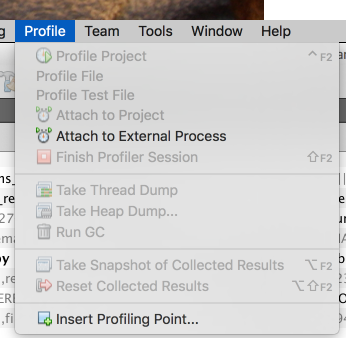
This new feature in Netbeans is very simple to use and there's no need to have the sources of the jsvs code. Off the Profile menu - > Attach to External Process
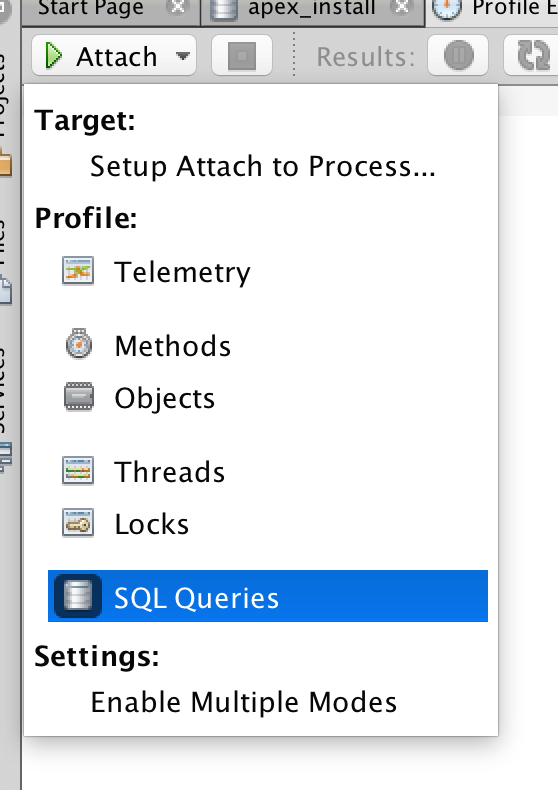
Then set the Profile to SQL Queries
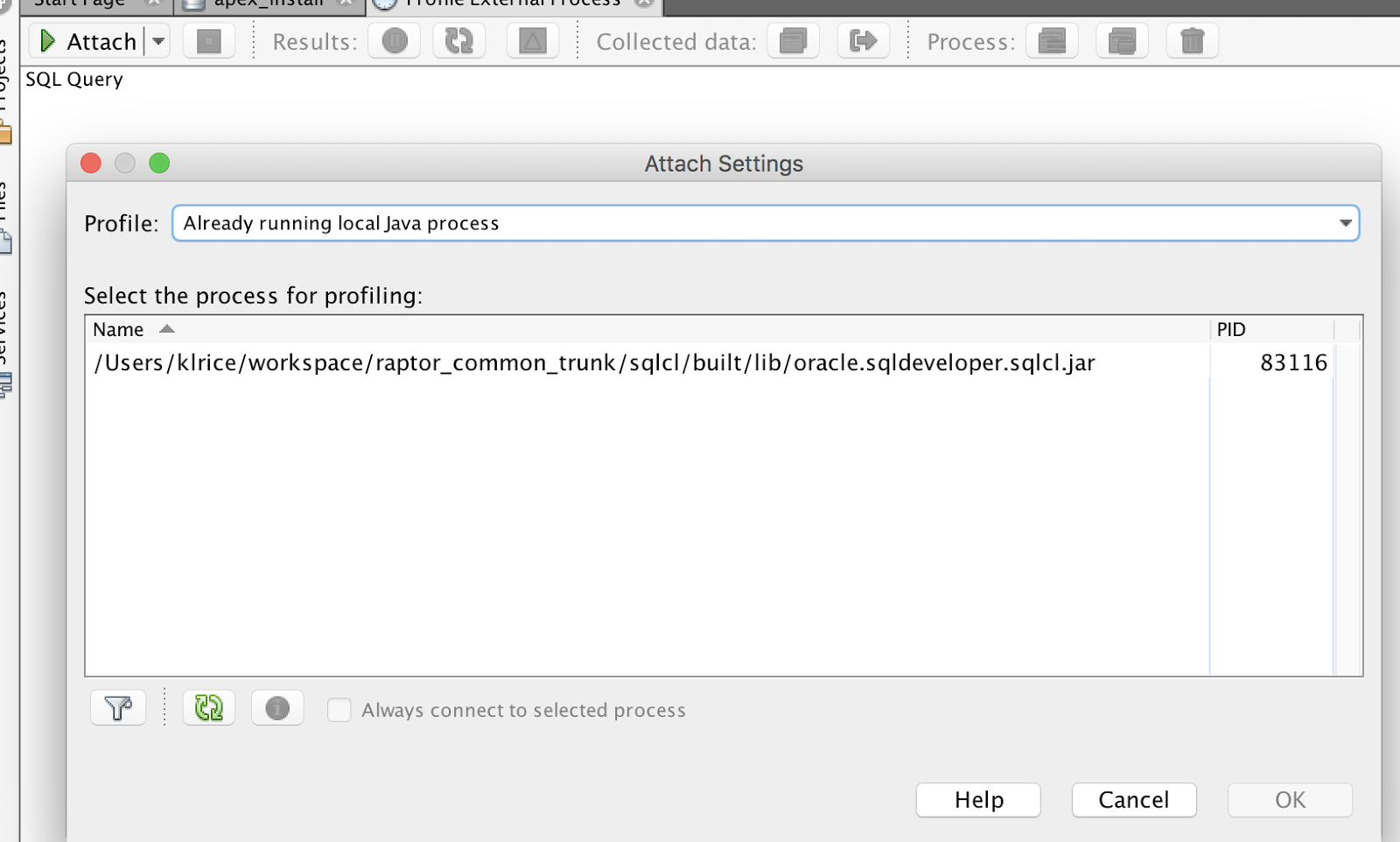
Click Attach, which shows a list of running java processes. This is what SQLcl will look like.
Running the Program
Now once JDBC traffic starts being issued, it's captured with timings and occurrences of that statement along with the Java stack for where the call originated. Next up is the hardest part, what the heck does all this data mean? When is fast , fast enough?What to change?
Below is what an APEX install looks like on my laptop during the middle of the process. There's a lot of data to look at. The slowest statement is the dbms registry validation. Is that bad, can it be sped up? Probably not. The most called is the check for DBMS_OUPUT. Can that be reduced? Also, probably not.
This is when knowledge of the code and intended actions are critical. For me, getting SQLcl the program from 19m down to 7m was fast enough. That was done with zero changes to the APEX install scripts but just from watching the traffic going to the database and analyzing that.
Change #1 : SQLcl was name resolving every create or replace <PLSQL OBJECT> then checking for errors on that object. Much faster is to simply check count(1) from user_errors without the name resolution. When there's no errors in the user_errors table, there's no need to name resolve. So that entire path was shortened. It's visible in this stack with the 1,106 time "select count(1) cnt from user_errors" was called.
Change #2: DBMS_OUTPUT was being called after any/all commands to the database. That was reduced to only calls that could invoke some output. For Example, alter session doesn't need to be checked. That change reduced the number of db calls being issued at all. Fastest call is the ones you don't make.
and on and on.
Nothing is more important than the knowledge of the intended outcome.
