REST Services Architecture
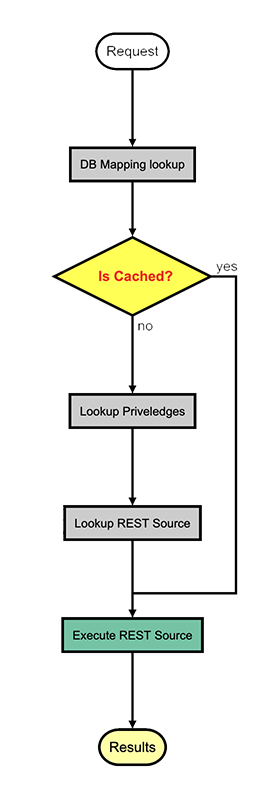
Oracle REST Data Services is a metadata based REST engine for the oracle database. That means the source code in sql or plsql that is executed is itself simply stored as rows in a table along with the privileges defined to protect these rest APIS. This means there is no deployment steps which allows very fast iterations while refining the code behind any REST APIs. This also means ORDS has to query source and metadata to then use to execute and fullfil the REST API. This is a highly development optimized approach so that everything is immediately reflected.
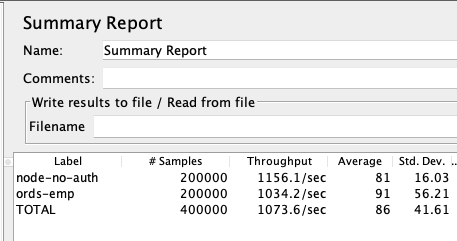
The performance of ORDS performing these metadata lookups is very tuned and results in quite good performance. This graph shows a simple test with 80 concurrent threads accessing a REST endpoint and resulting in over 200 requests per second. This is a test on my local laptop with the db in a docker, ORDS running on the host along with Jmeter.
ORDS 21.2 Metadata Caching
While this performance is probably plenty for many applications, faster is always better. New in ORDS 21.2 is the ability to cache the metadata lookups. The 2 settings are in the documentation here https://docs.oracle.com/en/database/oracle/oracle-rest-data-services/21.2/aelig/about-REST-configuration-files.html#GUID-37AA1468-DCB3-4D8B-868C-1910A0C04D68
The first setting is a simple boolean to enable/disable this caching.
cache.metadata.enabled true | false (default)
The second is how long to keep these in cache.
cache.metadata.timeout 30s ( default )
The formats accepted are based on the ISO-8601 duration format.
This would be what I would call production optimization. Unlike in development when the source of a REST apis could change very quickly, in production these change rarely and under a normal production patching / CICD type flow which makes them cache-able.
This change shortcuts the flow once cached.
Cached Performance
Using the same test as before the performance with a 1 minute cache goes from 200/s to over 1000/s.
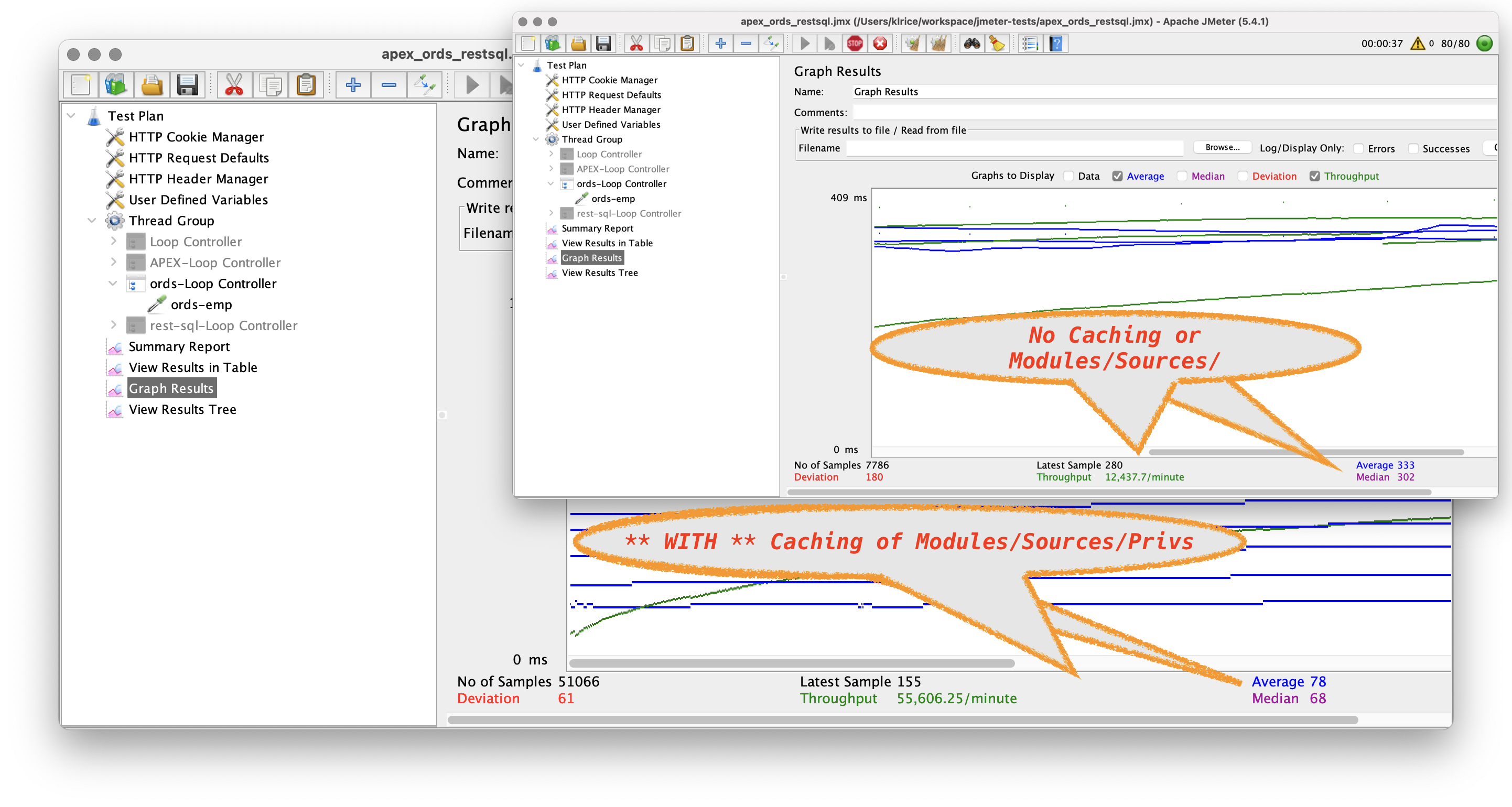
The caution here is in that 1 minute cache time if the rest source changes it will not get reflected. The only way to -force- a cache flush would be to restart the ORDS process which could performed in a rolling way over multiple ORDS processes with production updates/patching.
Perspective
I then questioned is this “Good” enough. This is probably the hardest question since there’s always a tad more to squeeze but at diminishing returns. For comparison, I created a simple Node/Express/OracleDB Driver script. This script , all ~60 lines of it, creates a connection pool, issued the same sql, and formatted the results the same. There was nothing more such as in ORDS metadata lookup, pagination,filtering,permissions, database pool lookups, no re-lookup source on cache timeouts, and many more things that the ORDS code paths deal with.
The results surprised me. You can let me know what you think. Performance is ~8% difference in throughput and get the benefits of everything ORDS has to offer.