Visualize and Analyze Strava Data on Autonomous Database
A new quickstart was published on Oracle Cloud Console’s homepage this week. This new quick start uses one of our Product Manager’s Strava data to show off how easy the new Dashboaring and Charting feature work in Database Actions ( sqldev-web ) with Autonomous Database.
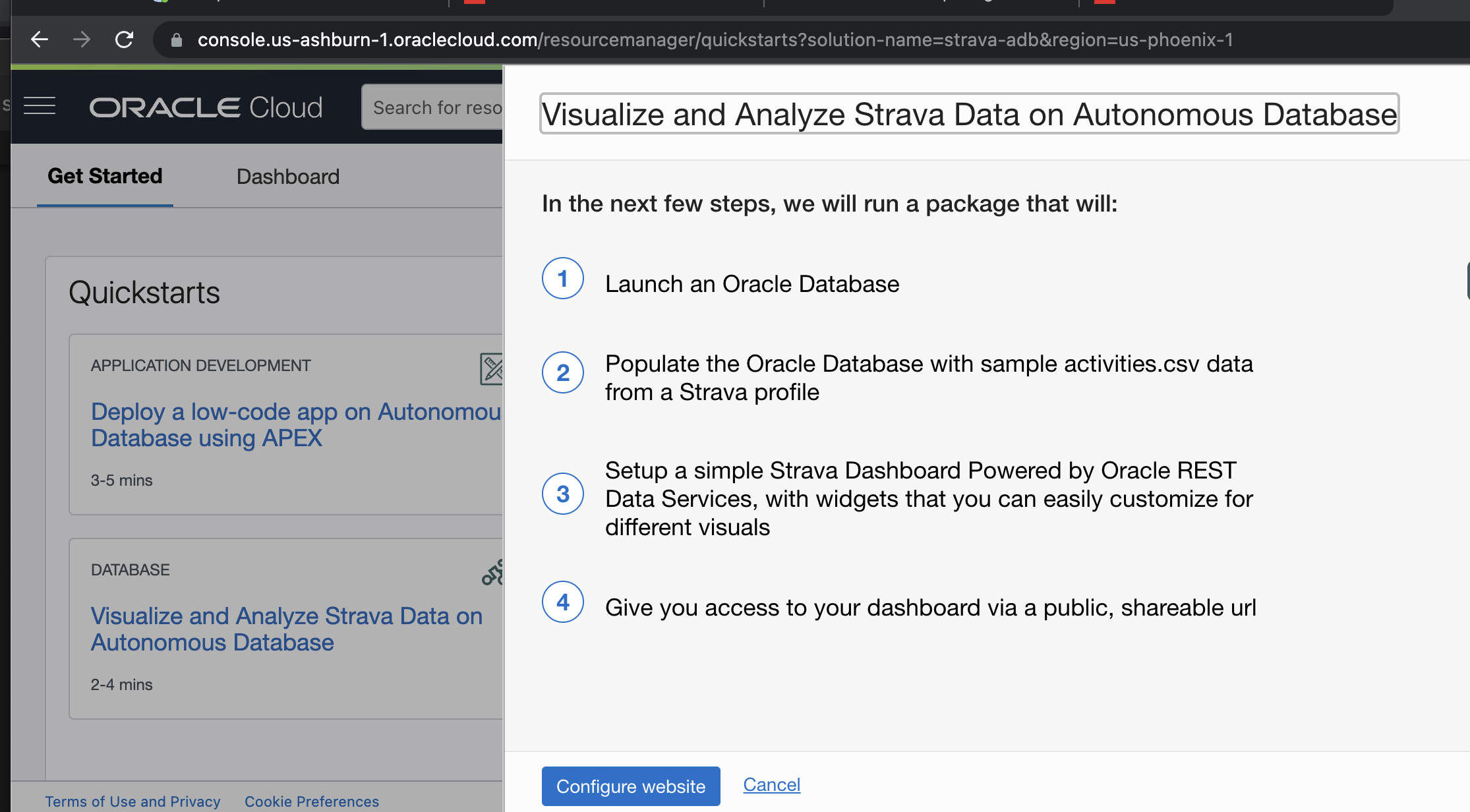
This quick start creates an Always Free Autonomous Database, loads the Strava Data, then produces a dashboard over it all.
Free
Oracle ALWAYS Free Tier is free, always offers many services including a free Oracle Autonomous Database. So for someone wanting to try this out for free, just sign up and kick the tires. There’s a number of other free services including compute, storage, function , containers,….

Use your Strava Data
After seeing this a number of Oracle Employees asked how to do this on their own data.
Getting the data from Strava
This is the scariest part because Strava for some reason connects Downloading your data to Deleting the Profile completely! They clearly did not consider the Developer Experience in folks wanting to get at their own data. This is a nice read on what the Developer Experience should be.
icymi - i wrote a thing about developer experience. https://t.co/6CGrnYNxJ2
— Go on then, drop it! (@monkchips) February 22, 2022
In the account page, there’s section at the bottom. Click the Getting Started.
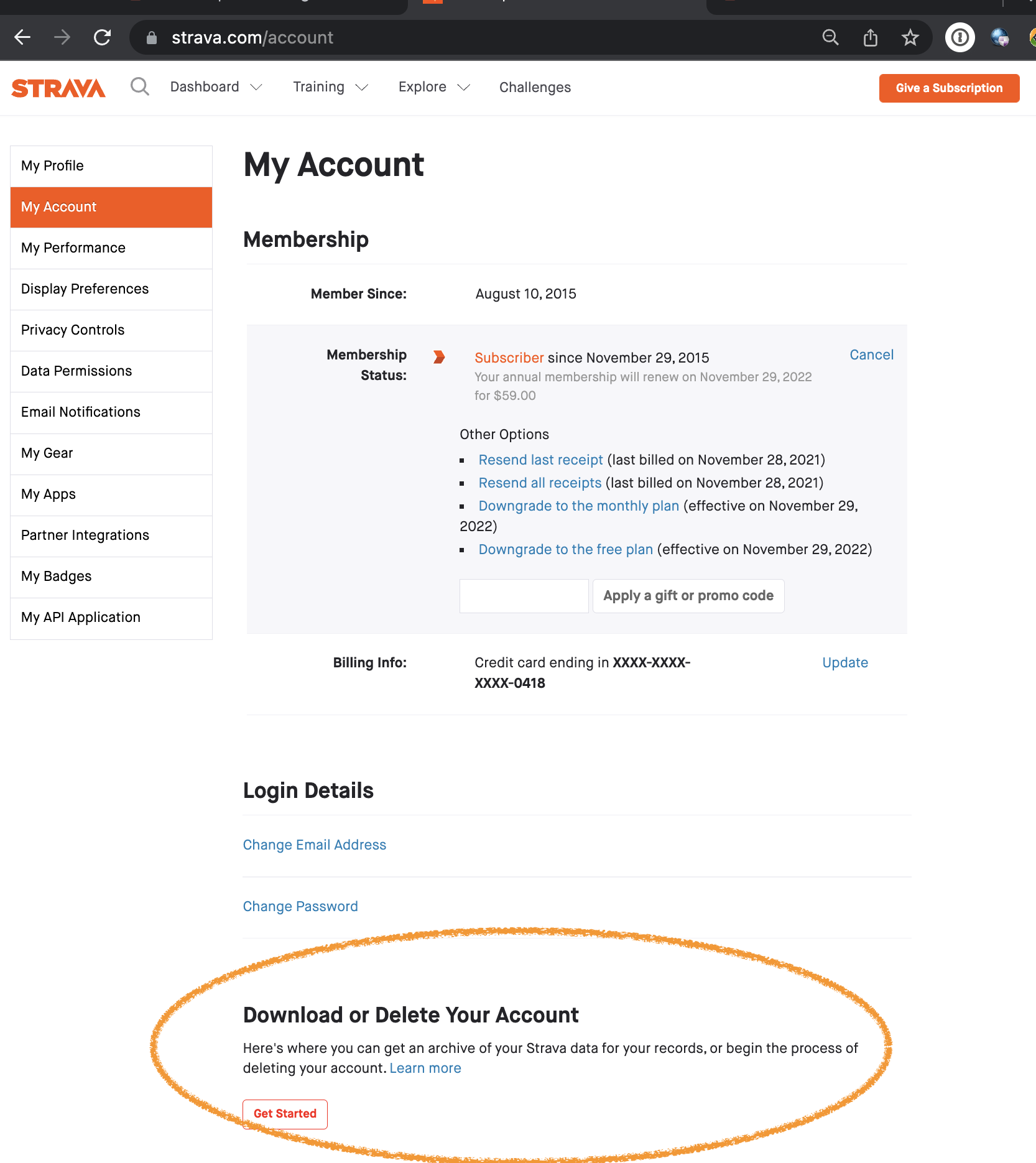
Now in section 2, click “Request your Archive”
Wait for an email

The email
Obviously click the download button.
Now Load the Data
I’m recommend make a new directory named strava and unzip into that. There’s everything in this zip including the gpx/fit/tcx files, images, authorized apps, every aspect of the Strava account.
LOAD into the database.
Now that you have the data in csv there’s many many ways to load the data. Some options are outlined here and here
SQLcl has for a long time had a load csv option. You can learn more about the generic from Jeff’s blog here from ‘19 SQLcl Load Command
This is the sql script which will load the data. It’s quite simple in that the 1st line set load scan_rows 10000 tells sqlcl how many rows to scan for auto calculating the data type and size. Without this if the first 10 rows column X is say 100 chars long then row 11 is 101, the load would blow out. This let’s it scan more and work out the type and length by scanning more data.
The next is 1 line per csv file load strava_activities activities.csv new The command load takes in the new table name, the file to load, and new meaning make a new table automatically.
SQLcl has always been able to run remote scripts making this gist running able straigh off github using the raw link or of course save to a local file and run it.
SQL> @https://gist.githubusercontent.com/krisrice/2b06df3ad4b51de278fe53672831f5ea/raw/99792be40b8881f0799700afb66ac991ed356512/load_strava.sql
SQLcl will scrub all the column names into Oracle Database column names such as this for the visibility_settings.csv. Again Developer Experience here is lacking w/Strava and these column names. The tool will report the before and after of the names such as>
#INFO COLUMN 1: Include your activities in Metro and Heatmap => INCLUDE_YOUR_ACTIVITIES_IN_MET
#INFO COLUMN 2: Who can see that you were part of a group activity => WHO_CAN_SEE_THAT_YOU_WERE_PART
#INFO COLUMN 3: Who can see your activity in Flybys => WHO_CAN_SEE_YOUR_ACTIVITY_IN_F
#INFO COLUMN 4: Who can view your training log => WHO_CAN_VIEW_YOUR_TRAINING_LOG
#INFO COLUMN 5: Profile Visibility => PROFILE_VISIBILITY
#INFO COLUMN 6: Default Activity Visibility => DEFAULT_ACTIVITY_VISIBILITY
SQLcl will also print out the full details per file for the load and what settings it used
Create new table and load data into table KLRICE.STRAVA_VISIBILITY_SETTINGS
csv
column_names on
delimiter ,
enclosures ""
encoding UTF8
row_limit off
row_terminator default
skip_rows 0
skip_after_names
batch_rows 50
batches_per_commit 10
clean_names transform
column_size rounded
commit on
date_format
errors 50
map_column_names off
method insert
timestamp_format
timestamptz_format
locale English United States
scan_rows 5000
truncate off
unknown_columns_fail on
SQL For-The-Win
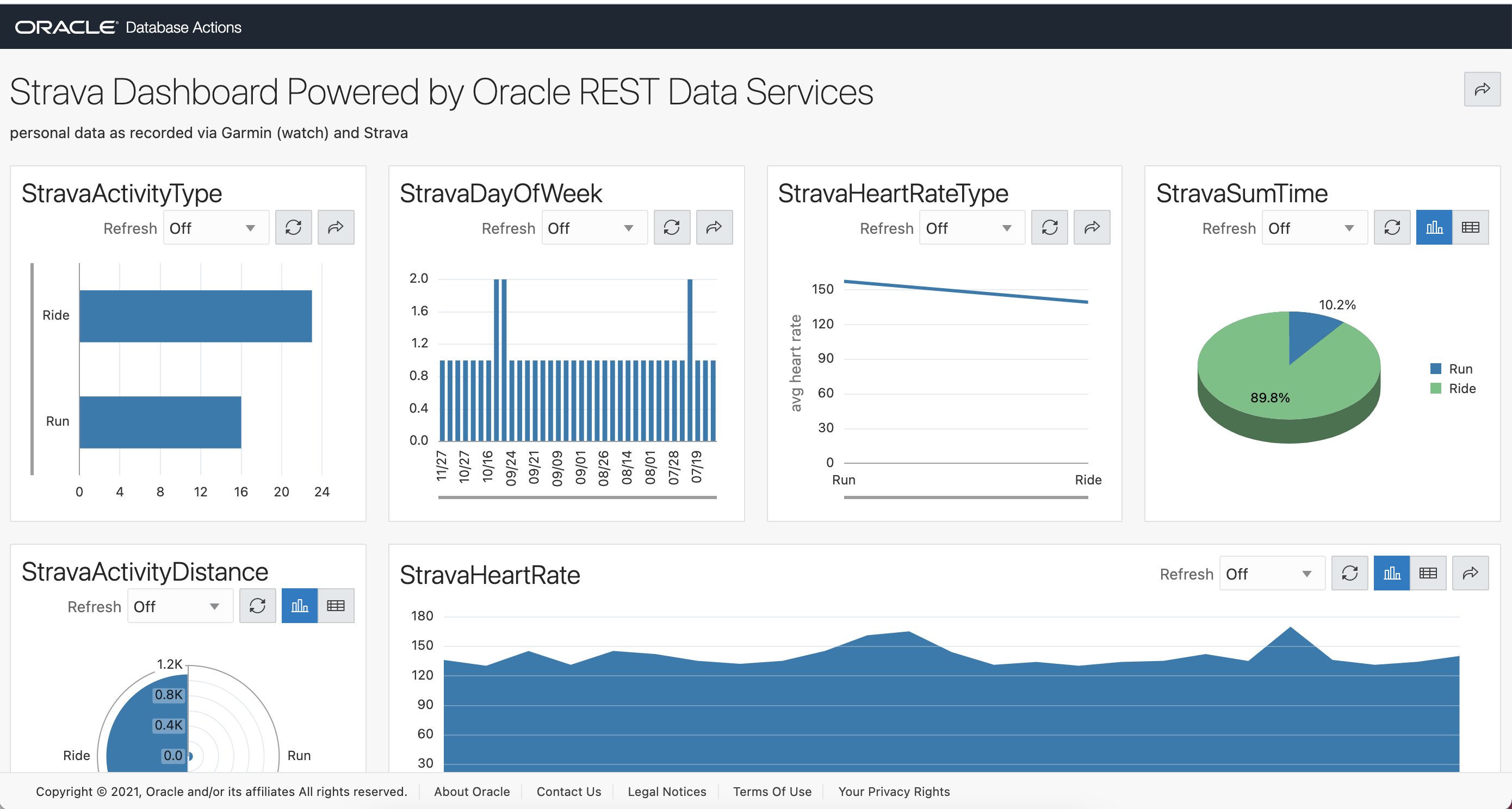
Now that it’s loaded into relational tables, have fun. For example, here’s my highest elevation things and most are in the virtual world of Zwift and a trip we did to see the mountain gorrillas in Bwindi Impenetrable Forest.
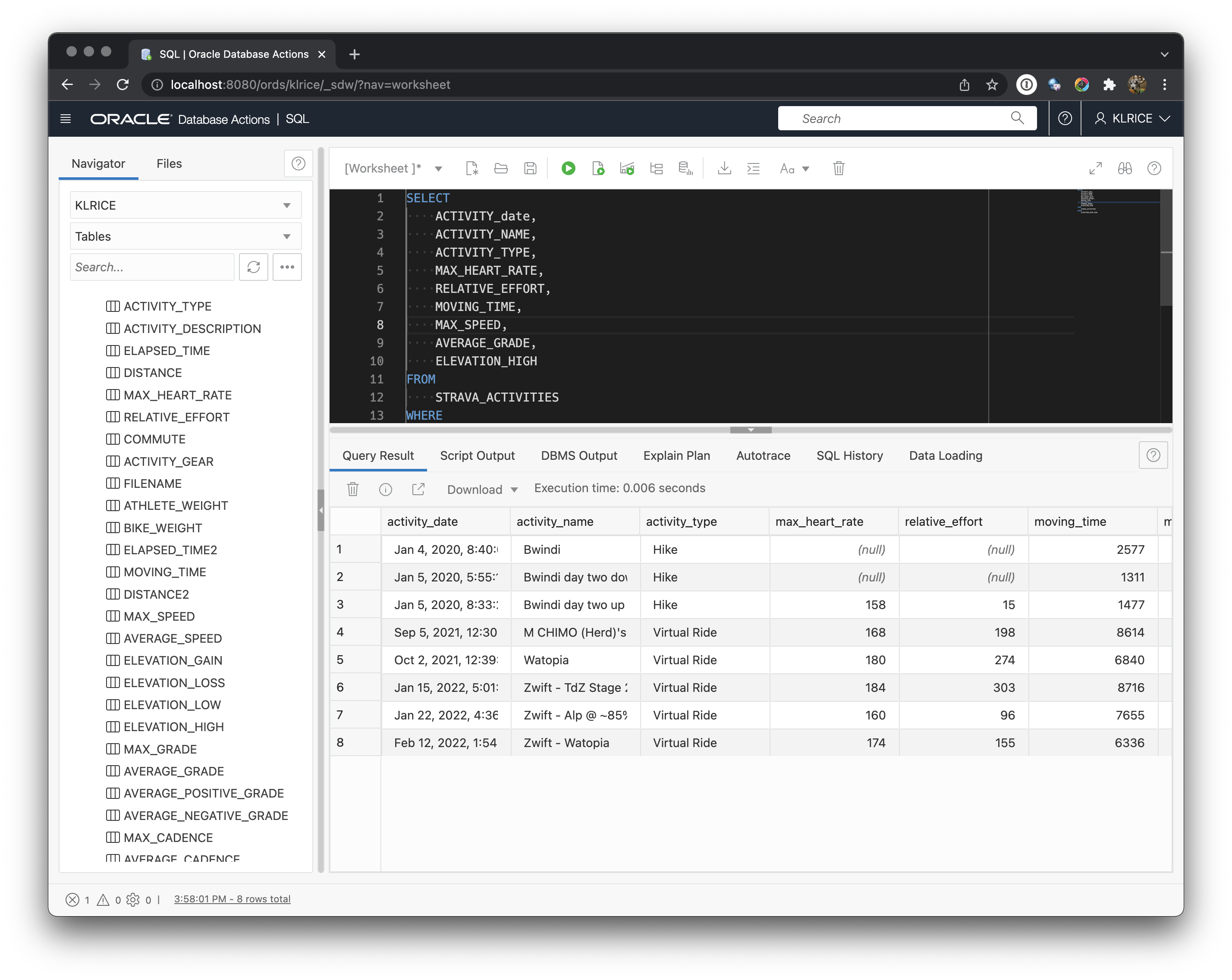
Good Luck. Happy SQL-ing